jueves, 31 de mayo de 2018
¡Buenas noches! Con todo lo visto concluimos la asignatura de Estadística, ahora toca repasar y hacerlo lo mejor posible en el examen. Espero que os haya servido cada tema y que a día de hoy sepáis al menos algo, o por lo menos espero que os quedéis con que la Enfermería también puede estar orientada a la investigación, que creo que es un matiz que no es conocido en la sociedad. La estadística nos permite observar datos y hacer inferencias, además de ayudarnos a tomar decisiones. Aquí concluimos esta asignatura, espero que sigáis consultando los problemas. Un saludo, nos volveremos a ver pronto. Gracias a todos.
martes, 29 de mayo de 2018
SEMINARIO 5
¡Buenos días! Estamos de vuelta con el último seminario de la asignatura en el que, como ya os comenté, teníamos que presentar nuestro trabajo de investigación, que consistía en la realización de una investigación a partir de la recogida de datos en cuestionarios.
Los componentes de mi grupo y yo, decidimos que nuestro tema sería la Calidad del Sueño en Estudiantes de Enfermería de la Universidad de Cruz Roja de Sevilla, puesto que consideramos que el sueño era un factor importante en nuestra universidad y grado.
Quisimos valorar la calidad del sueño de dichos estudiantes en función del sexo, compaginar estudios con trabajo, tener cargas familiares y el curso. Para ello, planteamos nuestras hipótesis, nuestros objetivos (conocer la calidad del sueño en función de las variables enumeradas), las variables y finalmente realizar nuestro test de hipótesis que en nuestro caso, fue preciso realizar Chi-cuadrado ya que hablábamos de variables cualitativas.
Como resultado obtuvimos que no había relación entre ninguna de las hipótesis propuestas, es decir, no había relación entre sexo y calidad del sueño, no había relación entre compaginar estudios con trabajo y calidad del sueño, no había relación entre curso y calidad de sueño y por último, no había relación entre tener cargas familiares y la calidad del sueño. Cabe decir, que quizás hayamos obtenidos estos resultados puesto que en el caso de sexo, había más mujeres que hombres y por tanto, las muestras que comparábamos no eran equitativas, al igual que nos ocurría con el trabajo y las cargas familiares.
Con esto, terminamos las entradas de los seminarios, pero continuamos con el último tema de la asignatura de Estadística: T-Student.
sábado, 26 de mayo de 2018
TEMA 12: "CONCORDANCIA Y CORRELACIÓN"
¡Buenos días! Como os dije aquí estamos en un nuevo tema donde aprenderemos a realizar problemas llamados "Regresión lineal". Comencemos con el tema:
Podemos realizar un estudio conjunto de dos variables. Las observaciones se pueden representar en un diagrama de dispersión o "scatter plot". En este diagrama, cada individuo es un punto cuyas coordenadas son los valores de las variables.

En nuestro caso, denominaremos a cada elemento de la ecuación de otra manera:
- Pendiente de la recta (a)= B1
- Punto de intersección con el eje de coordenadas b=β0
COEFICIENTES DE CORRELACIÓN:
Tenemos dos tipos de coeficientes, dependiendo de si las variables siguen una distribución normal:
- Coeficiente de Pearson (Paramétrica): si ambas variables siguen una normal
- Coeficiente de Spearman (No paramétrica): si ninguna de las variables sigue una normal o si sólo una de ellas sigue una normal.
¿CÓMO CALCULAMOS B0 Y B1?
B1:

B0:

DETERMINACIÓN:
Número adimensional (entre -1 y 1) que mide la
fuerza y el sentido de la relación lineal entre dos
variables. Lo calculamos a partir de la siguiente fórmula:

jueves, 17 de mayo de 2018
SEMINARIO 4
¡Buenos días! En el seminario 4 de la asignatura hicimos un breve repaso de lo que llevábamos explicado a lo largo de la asignatura y además introducimos nuevos problemas entre los que se encontraban Chi-cuadrado que ya lo expliqué en la entrada anterior, el Test de Student (lo explicaré próximamente) y Regresión lineal que explicaré en la siguiente entrada.
Nos ayudó mucho para repasar todo lo anterior y terminar de comprender completamente los términos y problemas. Nos vemos en Regresión lineal, espero que os resulte fácil.
miércoles, 9 de mayo de 2018
TEMA 11: "PRUEBAS NO PARAMÉTRICAS MÁS UTILIZADAS EN ENFERMERÍA"
¡Hola! Pues después de todo lo aprendido, comenzamos con lo que realmente son los problemas de Estadística en los que tendremos que aplicar los "pequeños problemas" que hemos ido aprendiendo a lo largo del blog. Comencemos con el primer tipo de ejercicio: Chi-Cuadrado
Para comenzar debemos saber que los tipos de ejercicios van en función del tipo de variables que tengamos, en este caso, Chi-cuadrado se emplea para variables cualitativas-cualitativas (dependiente-independiente).
CONDICIONES PARA APLICAR CHI-CUADRADO:
- Las observaciones deben ser independientes, no puede haber sujetos repetidos en más de una casilla.
- Utilizar en variables cualitativas
- Más de 50 participantes en la muestra
- Las frecuencias teóricas o esperadas en cada casilla de clasificación no deben ser inferiores a 5. Si son menores que 5, no podemos sacar conclusiones del contraste de hipótesis con Chi-cuadrado, las sacaríamos con con el Test de Fisher.
Veamos paso por paso cómo debemos realizar un ejercicio Chi-cuadrado:
1. Planteamos hipótesis nula y alternativas. Como recordamos, la nula es aquella en la que no se establecen diferencias entre hipótesis. Como ejemplo propongo un ejercicio en el que se pregunta ¿Existen diferencias en el consumo de
tabaco en función del sexo?:
- H0 (hipótesis nula): No existe asociación entre el sexo y el consumo de tabaco
- H1 (hipótesis alternativa): Existe asociación entre el sexo y el consumo de tabaco
2. Una vez que tenemos nuestras hipótesis planteadas, realizamos una tabla (llamada tabla de contingencia) para registrar los datos. En las tablas de contingencia, las columnas representan la variable dependiente y las filas, las variables independientes:

3. Planteamos nuestra fórmula de Chi-cuadrado que es la siguiente que os muestro:

Bien, ya sabemos cómo es nuestra fórmula, ahora debemos saber qué son las frecuencias observadas y las frecuencias esperadas.
Las frecuencias observadas son aquellos valores que tenemos en la tabla que calculamos en el paso 2. Es decir, la frecuencia observada de chicos que no fuman es 23, la frecuencia observada de chicos que fuman es 28 y así.
Para calcular las frecuencias esperadas, debemos realizar otra tabla:

Aplicándolo a nuestro ejemplo nos quedaría una tabla tal que así:

4. Una vez calculadas las frecuencias, podemos sustituir en la fórmula de Chi-cuadrado:

5. Una vez ya calculado el valor de Chi-cuadrado, debemos ver con qué hipótesis nos quedamos:
- Ho=No existe asociación entre el sexo y el consumo de tabaco (son
independientes) p=α>0,05
- H1=Existe asociación entre el sexo y el consumo de tabaco (son dependientes)
p=α≤0,05
Debemos calcular cuál es el grado de libertad, que se calcula de esta manera:
GL= (Número de filas-1)*(Número de columnas-1), en nuestro caso sería (2-1)*(2-1)= 1 GL
Para terminar el problema, debemos buscar en la tabla que os dejo pinchando aquí, el valor de chi observando el Grado de libertad 1 y una p=0,05, vemos que chi cuadrado en la tabla es 3,8415
Una vez observado el valor de chi en la tabla, debemos comparar este valor con el valor que nosotros hemos obtenido en nuestro problema. Si mi chi obtenida es menor a la chi de la tabla, nos quedamos con la hipótesis nula y si es más grande, nos quedamos con la alternativa.
0,00802222< 3,8415, por lo que podemos afirmar que nos quedamos con la Hipótesis nula, por lo que establecemos que no hay relación entre el sexo y ser fumador o no.
Espero que no os haya resultado difícil y que os pongáis manos a la obra, ya que con la práctica es como se llega a entender por completo. Nos vemos en el próximo tipo de ejercicio.
lunes, 7 de mayo de 2018
TEMA 10: "ESTIMACIÓN Y/O SIGNIFICACIÓN ESTADÍSTICA"
¿Qué es la significación estadística?
La significación estadística nos permite contrastar hipótesis y relacionarlo con el método científico. Nos permite tomar decisiones, cuantificando el error
HIPÓTESIS ESTADÍSTICA:
Es una creencia sobre los parámetros de una o más
poblaciones. Son conjeturas que se hacen antes de empezar el
muestreo. Pretenden comprobar si las diferencias encontradas en
la muestra del estudio se pueden generalizar a la
población. Tenemos dos tipos de hipótesis que planteamos antes de comenzar el estudio.
- Hipótesis nula (H0 ): contempla la no existencia de diferencias entre los parámetros que se comparan
- Hipótesis alternativa (H1 ): contempla la existencia de diferencias entre los parámetros que se comparan
Una vez que hemos formulado las hipótesis y realizado el estudio, las utilizamos para contrastarlas:
CONTRASTE DE HIPÓTESIS:
Con los intervalos nos hacemos una idea de un
parámetro de una población dando un par de números
entre los que confiamos que esté el valor desconocido.
Con los contrastes (tests) de hipótesis la estrategia es
la siguiente:
1. Establecemos a priori una hipótesis acerca del valor del
parámetro
2. Realizamos la recogida de datos
3. Analizamos la coherencia de entre la hipótesis previa y los
datos obtenidos
Sean cuales sean los deseos de los
investigadores, el test de hipótesis siempre
va a contrastar la hipótesis nula (la que
establece igualdad entre los grupos a
comparar, o lo que es lo mismo, la no que no
establece relación entre las variables de
estudio)
Se utiliza la prueba estadística correspondiente y se mide la
probabilidad de error al rechazar la hipótesis nula, asociada al
valor de p.
- p>0,05: en este caso no podemos rechazar la hipótesis nula (no podemos decir que sea cierta, sino que no podemos rechazarla)
- p<0,05: en este caso rechazamos la hipótesis nula, por lo que debemos aceptar la hipótesis la hipótesis alternativa.
EJEMPLO:
Yo sé que la media del peso de la
población española es de 70 kg.
- H0: yo creo que la media de los
fumadores pesa 70kg, no hay diferencia entre ser fumador y no ser fumador.
- H1: los fumadores tienen un peso
medio más alto que los no fumadores
- H2: Los no fumadores pesan más
que los fumadores.
Cojo una muestra aleatoria de
fumadores y calculo el peso medio, me sale 72 kg. Utilizamos un test de
hipótesis para ver si 72 kg es muy diferente a 70kg.
Si la media calculada me saliese muy diferente a mi pensamiento, el valor estaría en lo conocido como región de rechazo, y por tanto rechazaría la hipótesis nula.

ERRORES DE HIPÓTESIS:
- Con una misma muestra podemos aceptar o rechazar la hipótesis nula, todo depende de un error, al que llamamos α
- El error α es la probabilidad de equivocarnos al rechazar la hipótesis nula
- El error α más pequeño al que podemos rechazar H0 es el error p
- Habitualmente rechazamos H0 para un nivel α máximo del 5% (p<0,05)
- Es lo que llamamos “significación estadística”
MÉTODO DE CONTRASTE DE HIPÓTESIS:
Paso 1:
- Expresar el interrogante de la investigación como una hipótesis estadística. Planteamos las dos hipótesis
Paso 2:
- Decidir sobre la prueba estadística adecuada según la población y el tipo de variables
Paso 3:
- Seleccionar grado de significación para la prueba estadística
Paso 4:
- Realizar cálculos y extraer conclusiones
domingo, 6 de mayo de 2018
TEMA 9: "INTRODUCCIÓN A LA INFERENCIA ESTADÍSTICA. INTERVALOS DE CONFIANZA Y CONTRASTE DE HIPÓTESIS"
Como vimos en el primer tema, la inferencia estadística es el conjunto de procedimientos que nos permiten pasar de lo particular (muestra) a lo general que sería la población. Tenemos dos formas de inferencia estadística:
- Estimación del valor en la población a partir de un valor de la muestra.
- Contraste de hipótesis.
ESTIMACIONES:
Como hemos dicho, la estimación es el proceso de utilizar información
de una muestra para extraer conclusiones acerca de toda la población. A su vez, tenemos dos tipos de estimaciones:
- Puntuales: Consiste en considerar al valor del estadístico muestral como una estimación del parámetro poblacional. Por ejemplo: si tenemos que la tensión arterial sistólica de una muestra es de 125 mmHg, una estimación puntual sería considerar este valor como una aproximación a la tensión arterial media de la población.
- Por intervalos de confianza: Consiste en calcular dos valores entre los cuales se encuentra el parámetro poblacional que queremos estimar con una probabilidad determinada, habitualmente el 95%. Cuanto más estrecho sea el intervalo mejor, por ello es más eficaz la estimación por intervalos de confianza.
¿QUÉ ES EL ERROR ESTÁNDAR?
El error estándar mide el grado de
variabilidad en los valores del estimador en las distintas muestras
de un determinado tamaño que pudiésemos tomar de una
población.
Cuanto más pequeño es el error estándar de un estimador, más nos
podemos fiar del valor de una muestra concreta.
Depende de cada estimador, tenemos dos formas de calcularlo según de lo que se trate:
- Error estándar para una media: s/√¯n
- Error estándar para una proporción: √¯p(1-p)/n
CONTRASTE DE HIPÓTESIS:
La otra forma de inferencia estadística es el contraste de hipótesis como hemos mencionado anteriormente. Con los contrastes (tests) de hipótesis la estrategia es
la siguiente:
1. Establecemos a priori una hipótesis acerca del valor del
parámetro
2. Realizamos la recogida de datos
3. Analizamos la coherencia de entre la hipótesis previa y los
datos obtenidos
Los errores que podemos cometer en las hipótesis son los siguientes:
- Con una misma muestra podemos aceptar o
rechazar la hipótesis nula, todo depende de un
error, al que llamamos α
- El error α es la probabilidad de equivocarnos al
rechazar la hipótesis nula
- El error α más pequeño al que podemos rechazar H0
es el error p
- Habitualmente rechazamos H0 para un nivel α
máximo del 5% (p<0,05)
- Es lo que llamamos “significación estadística”
TEMA 8: "TEORÍA DE MUESTRAS"
Volvemos con un nuevo tema sobre el procedimiento muestral y los tipos de muestreo que tenemos:
Al conjunto de procedimientos que permiten elegir muestras
de tal forma que éstas reflejen las características de la
población le llamamos técnicas de muestreo. Siempre que trabajamos con muestras de la población, hay que asumir cierto error.
Si la muestra ha sido elegida por azar, se puede evaluar ese error y en este caso, se denomina muestreo probabilístico o aleatorio y a ese error se le denomina error aleatorio.
Los muestreos no probabilísticos, no usan el azar y por tanto no pueden evaluar el error.
¿QUÉ ES EL PROCEDIMIENTO MUESTRAL?
Pues como ya sabemos, el procedimiento muestral no es más que un método tal que al escoger un grupo de la población podamos tener un grado de probabilidad de que ese grupo pueda representar a la población.
TIPOS DE MUESTREO:
- No probabilístico: no utilizan el azar y no permite evaluar errores.No puede considerarse como una muestra representativa de la población.
- Por conveniencias: El investigador decide, según sus objetivos, los elementos que integrarán la muestra, considerando las unidades “típicas” de la población que desea conocer.
- Por cuotas: El investigador selecciona la muestra considerando algunos fenómenos o variables a estudiar, como: Sexo, raza, religión, etc.
- Accidental: Consiste en utilizar para el estudio las personas disponibles en un momento dado, según lo que interesa estudiar.
- Probabilístico: utilizan el azar. Me permite evaluar mi error aunque sea inevitable.
- Por conglomerados: Se usa cuando no se dispone de una lista detallada y enumerada de cada una de las unidades que conforman el universo y resulta muy complejo elaborarla. En la selección de la muestra en lugar de escogerse cada unidad se toman los subgrupos o conjuntos de unidades “conglomerados”
- Estratificados: Se caracteriza por la subdivisión de la población en subgrupos o estratos, debido a que las variables principales que deben someterse a estudio presentan cierta variabilidad o distribución conocida que puede afectar a los resultados.
- Aleatorios sistemáticos: Cada unidad del universo tiene la misma probabilidad de ser seleccionada.
- Aleatorios simples: Se caracteriza porque cada unidad tiene la probabilidad equitativa de ser incluida en la muestra:
- De sorteo o rifa: Meto 100 números en un bombo y saco 50 al azar.
- Tabla de números aleatorios: Se utiliza cuando la población es muy grande y no podemos emplear el sorteo o rifa.
Por último, el tamaño de la muestra va a depender de:
- El error aleatorio (estándar)
- De la mínima diferencia entre los grupos
de comparación que se considera
importante en los valores de la variable a
estudiar
- De la variabilidad de la variable a estudiar
(varianza en la población)
- El tamaño de la población de estudio
TEMA 7: "TEORÍA DE LA PROBABILIDAD"
¿Para qué nos sirve la probabilidad?
La probabilidad es muy útil a la hora de comunicarnos y entendernos. Se da una medida de ocurrencia de un hecho que no tiene la certeza de ocurrir pero nos da una esperanza de que el hecho anunciado se vea confirmado. Esto nos ayuda a tomar decisiones a la hora de realizar una opreación por ejemplo.
Tenemos varios tipos de probabilidad:
- Subjetiva o personalística: mide la confianza que el individuo tiene sobre la certeza de una proposición determinada. Este concepto ha dado lugar a la “Estadística Bayesiana” que explicaremos más tarde.
- Objetiva: se divide a su vez en dos:
- Clásica o "a priori": fue desarrollada para resolver problemas relacionados con los juegos de azar. Ejemplo: no hay que lanzar el dado para saber que la probabilidad “a priori” de que salga el 6 es de 1/6=0,16. La fórmula sería:


Dentro de esta probabilidad clásica tenemos la Ley de los Grandes Números, donde vemos que la probabilidad de que salga un número en el dado es 1/6= 16,6%. Puede que esta probabilidad no se cumpla, pero muchas veces la frecuencia realtiva de un suceso tiende a estabilizarse en torno al valor "a priori"
- Relativa o "a posteriori": Si el número de repeticiones de un experimento aleatorio es grande, podemos esperar que la probabilidad esperada se acerque a la probabilidad teórica.

¿QUÉ SON LOS EVENTOS O SUCESOS?
Cuando se realiza un experimento aleatorio, hay multitud de resultados posibles. El conjunto de todos estos posibles resultados se denomina espacio muestral (S). Entonces, ¿qué es el suceso? pues es el subconjunto de esos resultados, por ejemplo: las veces que salga cara o cruz en la moneda.
Ahora tenemos también evento complementario que es todo aquello que no sea salir cara en la moneda, o por ejemplo, yo llamo evento al número 6 del dado, cada vez que no salga 6 en el dado, será evento complementario.

El evento unión (AUB): Resultados experimentales que están en A o en B, no en los dos a la vez, por ejemplo: el evento A es ser mujer y el evento B es ser rubia. AUB sería la suma de ser mujer o la suma de ser rubia.

El evento intersección (AnB) está formado por la suma de los elementos que están en A y en B. Por ejemplo: A n B sería la suma de ser mujer y ser rubia, poseer las dos características.

Una vez que sabemos esto, podemos calcular probabilidades teniendo en cuenta varias propiedades:
- P (AUB):
- Cuando los sucesos de A y B se excluyen mutuamente: P (AUB) = P(A) + P(B)
- Cuando los sucesos de A y B no se excluyen mutuamente: P(AUB) = P(A)+ P(B) - P(AnB)
- P(AnB): A y B son sucesos independientes, la ocurrencia de uno no influye en el otro. P (AnB) = P(A)x (P(B)
TEOREMA DE BAYES:
Vincula la
probabilidad de A dado B con la probabilidad de B dado A. Por ejemplo: sabiendo la probabilidad de tener un dolor de cabeza teniendo gripe, se podría saber la probabilidad de tener gripe si se tiene dolor de cabeza.
DISTRIBUCIÓN DE PROBABILIDAD EN VARIABLES DISCRETAS:
- Distribución binomial: es un modelo matemático de distribución teórica de variables discretas
- Distribución de Poisson: se utiliza cuando los sucesos son impredecibles.
DISTRIBUCIONES NORMALES:
Gauss comprobó que la media coincide con la moda que es el punto más alto y con la mediana. En todas las distribuciones normales, si yo le sumo y le resto el valor de una desviación típica a la media de cualquier serie que siga una distribución normal, el valor de esa serie va a estar en el 68,27%

Extrapolando aparecen los principios básicos de
las distribuciones normales y podemos tipificar
valores de una normal:

lunes, 23 de abril de 2018
TEMA 6: "REPRESENTACIÓN GRÁFICA DE LA INFORMACIÓN"
Volvemos con una nueva entrada sobre las representaciones gráficas. Y la pregunta es...¿para qué sirven?
Pues bien, las representaciones gráficas soy muy útiles a la hora de comunicar la información, ofrecen una visión más clara de lo que se pretende comunicar.
¿CUÁLES SON LAS REPRESENTACIONES GRÁFICAS MÁS EMPLEADAS?
En cuanto a las variables cualitativas, tenemos las siguientes:
GRÁFICO DE SECTORES:
- Para variables dicotómicas o policotómicas con pocas categorías (3)
- No usar con variables ordinales
- Sólo muestra una variable a la vez. Por ejemplo: sexo (mujer/hombre)
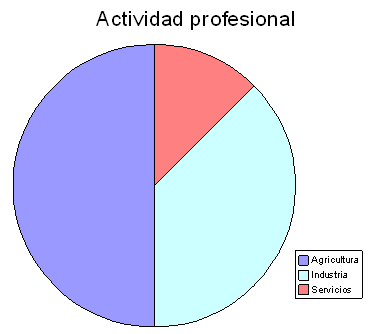
DIAGRAMA DE BARRAS:
- Cada barra representa una categoría y su altura la frecuencia (absoluta o relativa)
- Las barras deben estar separadas
- Es importante que el eje Y empiece en 0


PICTOGRAMA:
- Igual que el diagrama de barras pero las variables se representan con imágenes.

En cuanto a las variables cuantitativas, tenemos las siguientes:
GRÁFICO DE BARRAS:
- Igual que el explicado en variables cualitativas.
HISTOGRAMA:
- Los datos están agrupados en intervalos
- La base representa la amplitud de cada intervalo y la altura la frecuencia.
- Igual que el diagrama de barras pero la diferencia es que el histograma es para variables continuas

POLÍGONOS DE FRECUENCIA:
- Resulta de unir las marcas de clase de cada intervalo, todo esto sobre el histograma.

GRÁFICO DE TRONCO Y HOJAS:
- Es un híbrido entre la tabla y el histograma.
- Cada dato de la serie se divide en dos partes: el tronco (decenas) y la hoja (unidades)


TENDENCIAS TEMPORALES:

DIAGRAMAS DE DISPERSIÓN:


- Para representar un conjunto de variables cuantitativas y comparar entre diferentes unidades de análisis.
- Cada variable representa un vértice del diagrama de estrella.


Pues bien, las representaciones gráficas soy muy útiles a la hora de comunicar la información, ofrecen una visión más clara de lo que se pretende comunicar.
¿CUÁLES SON LAS REPRESENTACIONES GRÁFICAS MÁS EMPLEADAS?
En cuanto a las variables cualitativas, tenemos las siguientes:
GRÁFICO DE SECTORES:
- Para variables dicotómicas o policotómicas con pocas categorías (3)
- No usar con variables ordinales
- Sólo muestra una variable a la vez. Por ejemplo: sexo (mujer/hombre)
DIAGRAMA DE BARRAS:
- Cada barra representa una categoría y su altura la frecuencia (absoluta o relativa)
- Las barras deben estar separadas
- Es importante que el eje Y empiece en 0
PICTOGRAMA:
- Igual que el diagrama de barras pero las variables se representan con imágenes.
En cuanto a las variables cuantitativas, tenemos las siguientes:
GRÁFICO DE BARRAS:
- Igual que el explicado en variables cualitativas.
HISTOGRAMA:
- Los datos están agrupados en intervalos
- La base representa la amplitud de cada intervalo y la altura la frecuencia.
- Igual que el diagrama de barras pero la diferencia es que el histograma es para variables continuas
POLÍGONOS DE FRECUENCIA:
- Resulta de unir las marcas de clase de cada intervalo, todo esto sobre el histograma.
GRÁFICO DE TRONCO Y HOJAS:
- Es un híbrido entre la tabla y el histograma.
- Cada dato de la serie se divide en dos partes: el tronco (decenas) y la hoja (unidades)
Por último tenemos las representaciones gráficas para datos bidimensionales y multidimensionales:
TENDENCIAS TEMPORALES:
DIAGRAMAS DE DISPERSIÓN:
- Para representar dos variables continuas en un
grupo de individuos.
- En el eje “X” se representa la variable
independiente y en el eje “Y” los valores de la variable dependiente.- Para representar un conjunto de variables cuantitativas y comparar entre diferentes unidades de análisis.
- Cada variable representa un vértice del diagrama de estrella.
viernes, 13 de abril de 2018
SEMINARIO 3: "EPI INFO"
¡Buenas tardes! En este seminario aprendimos a utilizar Epi Info, que es un software diseñado para los profesionales de la salud pública e investigadores, con el fin de crear cuestionarios y bases de datos. Hoy aprenderemos a crear cuestionarios usando esta aplicación paso a paso. ¡Empecemos!
El primer paso que tenéis que realizar es descargar esta aplicación en el enlace que os dejo:
https://www.cdc.gov/epiinfo/support/downloads.html, hacemos click en "DOWNLOAD INSTALLER". Una vez que lo tenemos descargado, al abrir la aplicación nos saldrá una ventana como esta:

Le damos a CREAR FORMULARIOS, nos aparecerá una página como la que os pongo aquí abajo y le damos a nuevo proyecto.

Como utilizaremos Epi Info para la realización de cuestionarios ya que nos facilita el trabajo a la hora de agrupar las respuestas, sólo mostraré las principales herramientas aunque tenéis muchísimas opciones.
TÍTULO:
Para ponerle título a nuestro cuestionario haremos click en "Título", lo he subrayado en naranja, y después nos aparecerá una pantalla en la que pondremos el Título que queramos, yo puse "Toxiinfecciones"

TEXTO:
Lo utilizaremos para crear una casilla en la que los participantes puedan poner su nombre. Pinchamos en "Texto" y repetimos el mismo procedimiento que antes.

NÚMERO:
Para que los participantes puedan poner su edad. Elegiremos el patrón "##" para que la edad pueda estar comprendida entre 0-99, si queremos que la edad esté comprendida entre 0-9 años elegiremos "#" y así con todos.

OPCIÓN:
Con esta opción daremos a elegir a los participantes una serie de elementos que marcarán según su situación o preferencia.

SÍ/NO:
Con este campo los participantes marcarán la opción según estén enfermos o no por ejemplo.

CASILLAS:
Es un campo similar al de "Opción", lo utilizamos para saber qué opción eligen los participantes en función de las que les presentemos.

Una vez que elaboramos nuestro cuestionario en Epi Info, pasamos a introducir los datos recogidos en los cuestionarios pasados anteriormente, para así agruparlos fácilmente. Para ello pinchamos en GRABAR DATOS.
Una vez que hayamos pasado los datos de todos los cuestionarios que tenemos, le damos a LISTADO DE REGISTROS para así agrupar los datos en una tabla.
Si queremos un gráfico con los resultados obtenidos para verlo más claro, le damos TABLERO VISUAL. Pulsamos el botón derecho y le damos FRECUENCIAS y obtendremos la frecuencia de lo que busquemos, frecuencia de enfermos, frecuencia de personas que prefieren helado de vainilla...
Aquí termina el seminario chicos! Espero que os haya servido de ayuda este seminario y utilicéis esta aplicación a la hora de realizar cuestionarios, resulta mucho más sencillo y rápido que estar contando uno a uno!!
domingo, 8 de abril de 2018
TEMA 5: "MEDIDAS RESUMEN PARA VARIABLES CUANTITATIVAS"
Además de las tablas podemos resumir una serie de
observaciones mediante “estadísticos”. Tenemos tres tipos de medidas estadísticas:
MEDIDAS DE TENDENCIA CENTRAL:
Dan idea de los valores
alrededor de los cuales el resto de los datos tienen
tendencia a agruparse. Dentro de este grupo tenemos:
- Media aritmética: Se calcula para variables cuantitativas y se trata del centro geométrico de nuestros datos. Tenemos dos fórmulas. Cuando los datos están desagrupados, utilizamos esta fórmula:

Cuando los datos están agrupados utilizamos esta fórmula, siendo mc la marca de clase que se calcula en la tabla de frecuencia sumando los extremos del intervalo y dividiéndolo entre 2.

- Mediana: Es el valor de la observación tal que un 50% de los datos es menor y otro 50% es mayor. Si el número de observaciones es impar el valor de la observación será justamente la observación que ocupa la posición (n/2)+1 – Si el número de observaciones es par, el valor de la mediana corresponde a la media entre los dos valores centrales, es decir, la media entre la observación n/2 y la observación (n/2)+1
- Moda: Es el valor con mayor frecuencia (que más veces se repite) – Si hay más de una se dice que la muestra es bimodal (dos modas) o multimodal (más de dos)
MEDIDAS DE POSICIÓN:
Dividen un conjunto ordenado de datos
en grupos con la misma cantidad de individuos.
Los cuantiles más usuales son:
- Percentiles: Valor del elemento que divide una serie de datos en cien grupos de igual valor o en intervalos iguales. El P50 corresponde con el valor de la mediana puesto que la mediana, como hemos dicho, es justo el 50%.
- Deciles: Dividen la muestra ordenada en 10 partes. El D5 corresponde con el P50 y con la mediana.
- Cuartiles: Dividen la muestra ordenada en 4 partes:
- El Q1 , primer cuartil indica el valor que ocupa una posición en la seria numérica de forma que el 25% de las observaciones son menores y que el 75% son mayores.
- El Q2 , segundo cuartil indica el valor que ocupa una posición en la seria numérica de forma que el 50% de las observaciones son menores y que el 50% son mayores. Por tanto, el Q2 coincide con el valor del D5, con al valor de la mediana P50
- El Q3 , tercer cuartil indica el valor que ocupa una posición en la seria numérica de forma que el 75% de las observaciones son menores y que el 25% son mayores.
- El Q4 , cuarto cuartil indica el valor mayor que se alcanza en la seria numérica
Dan información acerca de la heterogeneidad de nuestras observaciones.
- Rango o recorrido: Diferencia entre el mayor y el menor valor de la muestra |xn -x1|
- Desviación media: media aritmética de las distancias de cada observación con respecto a la media de la muestra:
- Desviación típica: cuantifica el error que cometemos si representamos una muestra únicamente por su media
- Varianza: expresa la misma información en valores cuadráticos.
- Recorrido intercuartílico: Diferencia entre el tercer y el primer cuartil

- Coeficiente de variación: es una medida de dispersión relativa (adimensional) ya que todas las demás se expresan en la unidad de medida de la variable. Nos sirve para comparar la heterogeneidad de dos series numéricas con independencia de las unidades de medidas:

DISTRIBUCIONES NORMALES:
Es una de las distribuciones de probabilidad de
variable continua que con más frecuencia aparece
en fenómenos reales. La gráfica de su función tiene una
forma acampanada y es simétrica respecto de los
valores posición central (media, mediana y moda,
que coinciden en estas distribuciones)

Asimetrías:
Grado de asimetría de la
distribución de sus datos en torno a su
media. Puede tener estos resultados:

- Si g1=0, tenemos una distribución simétrica
- Si g1>0, tenemos una asimetría positiva
- Si g<0, tenemos una asimetría negativa
Curtosis:
Grado de concentración de valores que se encuentran en torno a la media, adopta valores entre -1 y 1. Puede tomar estos valores:
- g2 = 0 (distribución mesocúrtica)
- g2 > 0 (distribución leptocúrtica).
- g2 < 0 (distribución platicúrtica)

SEMINARIO 2: "BÚSQUEDAS BIBLIOGRÁFICAS"
Como ya os comenté hemos tenido que realizar un trabajo sobre las búsquedas bibliográficas interrogando a las bases de datos. El trabajo que se nos encomendó trataba sobre qué intervenciones enfermeras eran más eficaces en pacientes con Diabetes Mellitus Tipo II, si las intervenciones enfermeras individuales o las grupales. ¡Comencemos con el trabajo!
En primer lugar, como ya sabemos, elaboramos la pregunta PICO:

De tal forma que la pregunta quedó así: ¿Son
más eficaces las actuaciones enfermeras educativas
individuales
que las de carácter grupal en pacientes de un centro de salud
urbano con Diabetes
Mellitus Tipo II,
para aumentar la adherencia al régimen terapéutico?. Siendo las palabras subrayadas, las palabras que debíamos buscar en los tesauros.
Tesauros:

Búsqueda de artículos mediante Booleanos:




Conclusión:
Como conclusión obtuvimos que para mejorar la adherencia al tratamiento en pacientes con Diabetes Mellitus Tipo II, es más eficaz la realización de ambas intervenciones, primero una grupal y luego realizar un seguimiento individual.
Suscribirse a:
Entradas (Atom)